
想着记录一下平时分析过的 crash dump,作为一个总结和参考。不过因为涉及到公司代码,所以一些细节没法描述太明白,crash 堆栈和对应的源代码也不方便贴出来了。这里先整理了几个比较有代表性的,其他一眼就能看出问题的就不写到这里了。
2023.Q3 ui 代码没有清理 framework api 指针
当用户开启计算机锁屏时自动切断 channel 的策略并触发了锁屏行为后,UI 会调用 api 切断所有 channel,并且立即清理上层保存的数据,但问题就在这个清理上。
原本调用触发切断的 api 后会有一个回调通知,上层是在回调里做清理动作的。但是现在代码中主动调用了一个 channel_mgr.Clear();,这个 Clear() 函数里清理的不完全,相比之下另一个成员函数 Delete(channel_id) 才是做到了彻底清理。同时回调函数里还做了许多额外的清理操作,这里一个 Clear() 把其他操作也都忽略掉了。
其实究其原因就是外部保存了 ChannelItem 的裸指针,但是又存在这样一个 corner case 没有将它清理掉,等 ChannelItem 实例析构后这个指针就野了。关键在于怎么发现这个代码路径。
因为 framework 层在释放前总是会通过回调函数通知 UI 清理,费好大劲排除 framework 没有漏掉的地方后把目标放到了 UI 上。来来回回翻代码后才发现这个地方。
2024.Q2 释放对象后没有通知导致其他类持有野指针
某个产品在 web 上有个 move division 操作,move 后 client 就会收到用户被删除的通知,随后 client 会反初始化该产品使用到的相关组件和资源。之后只要用户退出到登录界面,再重新登录时 client 就会 crash。
查看堆栈发现跟 ipc 对象有关,ipc 资源也是上面 client 清理操作的一部分。代码中这个类是 ipc 消息的一个 handler,保存新的 ipc 指针前会将 this 指针从当前 ipcserver 的 handlers 里面移除,而堆栈就是挂在这里,可见是前一个 ipcserver 指针野掉了但是没通知这个类去清理。
自从 framework 代码重构后到处都在设置 ipcserver,一时间很难从日志或者代码中看出哪一个操作忘记通知到这个类做清除操作。好在问题容易复现,调试几次后发现是在 client 收到删用户的通知后做退出清理时,ipc 实例终止并释放后没有通知相应的回调做指针的清理,导致这个 module 对象中持有的 ipcserver 指针失效。真是灯下黑了。这个问题同上一个一样,原因是挺直白的,但是要从众多代码里找到触发条件需要耐心和仔细去分析。
修改只要加上指针清理的通知即可。
指针设置的地方多了之后就很难管理和一一通知更新,可以考虑用 shared_ptr + weal_ptr 组合避免指针失效。也可以使 ipcserver 指针成为一个创建后就不变的变量,它内部实际的 ipc 连接再根据需要创建或断开即可。或者就一直保持着这个通道,没有业务就不发数据,直到下次重启 client。总之避免需要通知所有对象更新指针的操作。
2024.Q2 容器访问越界
这个问题在三个月前的版本上线后就出现了,不过 iOS 平台我这边关注的少,平时看 windows 比较多,毕竟用户量大。然后公司 QA team 也没有发现这种问题,所以最近才从 iOS team 那边了解到情况。但是和同事探讨后发现,这个问题应该是早在大半年前就出现了,但是那个时候数量很少也就没有引起关注,三个月前 iOS 那边做了一些优化后 crash 的数量增加了很多,这才引起关注。而且优化后 crash 堆栈有所变化,一下子还认不出来。
其实怀疑是不是跟上面 Mac 那个野指针 crash 一个原因,只不过 iOS 的堆栈跟它不太一样。看了汇编后发现是挂在访问容器元素的虚表,准备做虚函数调用的地方——所以我才这样想了,然后花了不少时间找是不是 ipc_server 的 handler 注册后但是自身析构时又忘记清除了。找来找去并没有头绪,半放弃状态了。最后还是找领导一起研究了一会然后点醒了我:有可能是 ipc_server 类自己析构了,然后通过 vector.end() 作为终止条件的 for 循环就会越界,越界后那迭代器拿着的可不就是一个“野指针”么。看来我的思维还是不够开阔,有些僵化了。
不过 iOS 上相应功能还在开发,所以很可惜跟上面 Mac 那个析构并不是同一个原因。
ipc 通常有一个 ipc_server 和 ipc_client,使用的结构就是常见的生产者消费者模型,各自会有一个 HeartBeat() 定期从队列里取出数据处理。但 iOS 上有个问题,它们会立即触发一次 HeartBeat() 以加速消息的处理,因为实际上是同一个进程,这样可以避免等待下一次心跳而立即处理消息。比如有这样一个 Flush() 函数,里面先后调用一次 ipc_client 和 ipc_server 的 HeartBeat() 函数
void T::HeartBeat() {
// ... other codes
for (auto it = handers.begin(); it != handers.end(); ++it) {
if (*it) (*it)->HandleXXX(...);
}
}
void Flush() {
if (ipc_client) ipc_client->HeartBeat();
if (ipc_server) ipc_server->HeartBeat();
}
考虑这种场景:
- 有消息从 ipc_client 发到 ipc_server
- 常规触发(比如通过 idle 循环或定时器等) ipc_server 的 HeartBeat() 函数,处理队列里的消息
- 上一步的操作可能会发送一些新的消息到 ipc_client 队列中
- 调用 Flush() 触发两个 HeartBeat(),处理消息
- ipc_client 的 HeartBeat() 处理收到的消息,处理过程中可能也会发一些消息到 ipc_server
- ipc_client 的 HeartBeat() 返回,进入 ipc_server 的 HeartBeat(),处理队列中的消息,处理过程中又往 ipc_client 发消息,部分消息发送之后又会立即调用 Flush()
从第 4 步开始就有 HeartBeat() 重入的情况了。
HeartBeat() 代码中处理 ipc 消息就是 for 循环遍历 handler 的 vector,实际使用中 handler 会在某一些回调函数里继续增加删除其他 handlers,而我们又知道 vector 的 push_back 可能会造成迭代器失效,那么当前 handler 返回后迭代器 ++ 时就可能会挂掉。
之前为了避免这个问题我们简单地将 vector reverse 了相对大的数量,同时移除 handler 时只把指针置空,不从 vector 里 erase。erase 操作延迟到 HeartBeat() 函数返回之前进行。
而现在 iOS 上通过 Flush() 函数让 HeartBeat() 里也嵌套调用了 HeartBeat(),那么当后一个 HeartBeat() 中满足条件 erase 指针减小了 vector 的 size,之后函数返回,前面一个循环中的迭代器偏移可能就超出了 end() 的位置,也就会访问越界,里面的数据自然就是一个“野指针”了。
比如 vector 里有 10 个元素,当前循环到第 6 个,中途触发 erase 把元素删到剩 3 个,然后 it != vec.end() 判断无法终止循环,因为 it 已经大于 end() 了。

framework 做回调通知时还是需要留意,谁也不知道其他模块会在这些回调函数里写了什么代码,甚至在回调里删除 framework 对象的也有。
2024.Q3 模板定义不同导致访问偏移错误
某一天发现 app 的新包启动就 crash,分析 dump 发现挂了给某个类设置 callback 指针的地方。但是却很奇怪,汇编里看到设置指针的目标地址偏移却是错的。代码中设置的偏移是 this+234 byte,但是用 dt 命令查看该类的 callback 成员实际上是位于 this+264 byte。因为这个 callback 是自带引用计数的,那么当 234 byte 位置上数据是非 0,设置不同指针时就会自动对“原指针”减引用计数,而实际 234 byte 上的数据根本不是合法的指针,那么自然也就会导致 crash 了。
接下来主要就看为什么会编译出来会有偏移错误的情况了。这个其实跟跨模块访问对象的情况挺像,举例说模块 A 的工厂函数生产对象 A,它用了如下的新定义,
struct SA {
int i1[10];
int i2;
int i3;
}
而模块 B 包含了模块 A 老版本的头文件,里面的定义是
struct SA {
int i1[6];
int i2;
int i3;
}
那么当 B 和新版本的 A 一起运行,B 访问的 i3
实际上是 i1[7]
,那自然就会有问题。
而这次不仅仅是跨模块,在同一模块内部也会发生这种现象,下面来看这段代码,它们各自写在不同的 .cpp 和 .h 里。
// vvv header1.h vvv
#ifndef HEADER_H_
#define HEADER_H_
#include <string>
template<typename... Args>
struct TestTemplate {
int i1{1};
int i2{2};
std::string s1;
int i3{3};
};
#endif
// ^^^ header1.h ^^^
// vvv header2.h vvv
#ifndef HEADER_H_
#define HEADER_H_
template<typename... Args>
struct TestTemplate {
char i1{1};
char i2{2};
};
#endif
// ^^^ header2.h ^^^
// vvv src2.h vvv
#pragma once
#include "header2.h"
struct Wrap {
TestTemplate<int> member;
};
Wrap* CreateTestTemplate();
// ^^^ src2.h ^^^
// vvv src2.cpp vvv
#include "src2.h"
Wrap* CreateTestTemplate() {
return new Wrap();
}
// ^^^ src2.cpp ^^^
// vvv src1.cpp vvv
#include "header1.h"
#include "src2.h"
int main() {
TestTemplate<std::string> s1;
Wrap* s2 = CreateTestTemplate();
s2->member.i3 = 33; // memory corruption
return 0;
}
// ^^^ src1.cpp ^^^
关键就在它们用了相同的 include guard,因为 main 函数中的 s2 是在 src2.cpp 中以 header2 的定义创建,而在 main 函数里却按照 header1 的方式去访问,那就会导致访问到错误的地址。
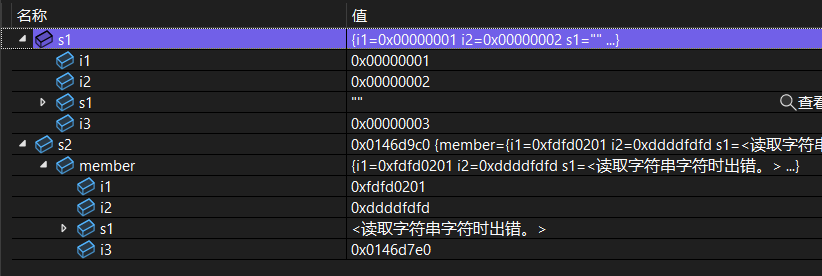
这个问题实际上是我们代码仓库里在另一个路径中藏了一份老版本的实现一直没有删,然后其他同事在改代码过程中偶然使其他 cpp 包含到了这个头文件,最后形成了示例代码中的局面,好在问题很容易复现,所以查起来还是省力的。
其实不写这个 include guard,直接用 #pragma once
就行,编译器编译时就会直接报符号重定义了。
