
主要功能
根据定义的 ID 列表下载每个画师的所有插画
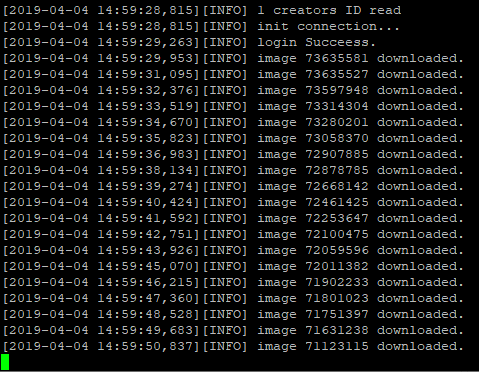
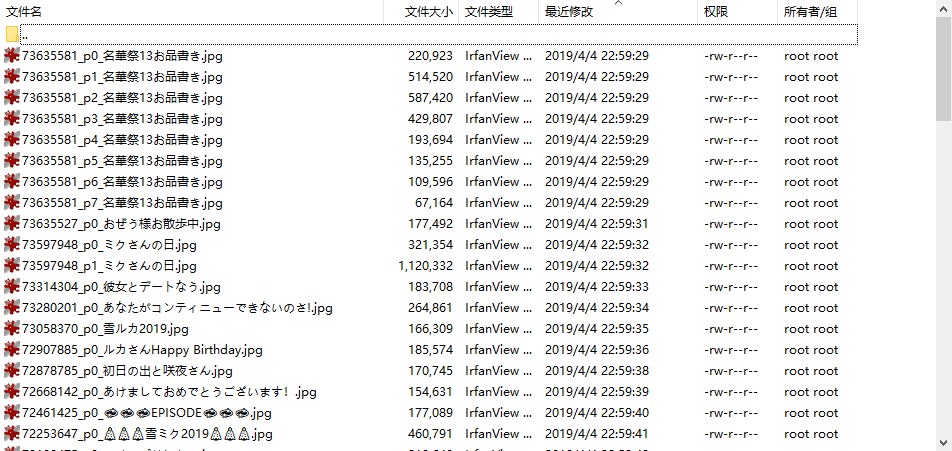
下载链接
如何使用
- 需要安装 python 3.7 环境,并安装 demjson 依赖库。
- 解压文件包,在 pixivspider-data 目录下的 config.ini 文件中填入有效的 P 站账号以及对应密码用于正常访问 P 站。账号中的浏览限制选项不打开会影响部分插画的下载,需要下载则在网页中打开。
- 添加准备下载的画师 ID,以下方式选一种即可
- 数据库文件不存在(首次使用):使用导入方式自动生成,参看导入部分,比较推荐此种方式,方便快捷。
- 数据库文件不存在(首次使用):直接运行
python pixivspider
命令(命令行的工作目录设置为 pixivspider 所在目录),会自动在 pixivspider-data 目录中生成 download.db 数据库文件,随后手动添加 ID 到数据库中,见下方手动添加部分。
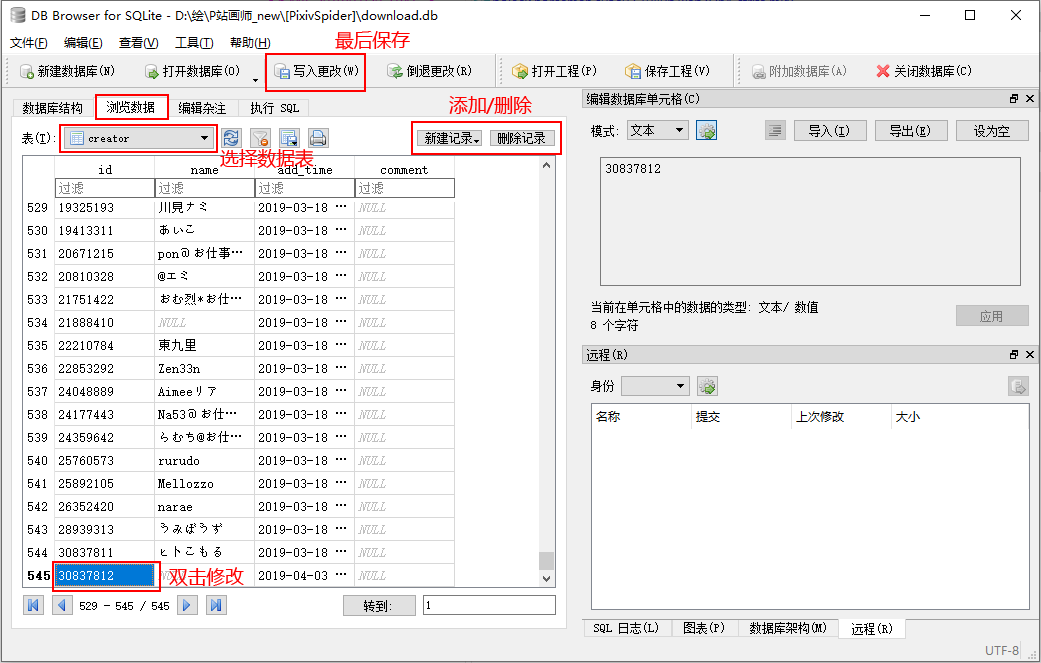
- 手动添加/修改画师 ID 列表:使用 DB Browser for SQLite (下载)打开已存在的数据库文件 download.db ,切换到 creators 数据表,手动添加/修改相应的 ID,最后保存退出即可
- 运行之前需要确保能正常访问 P 站,因为脚本没做代理的处理,所以代理需要设为全局以便雨露均沾,能有外网机器的话推荐直接仍上去跑。至于如何改善国内这差劲的网络环境这一步不在此文说明范围。。。
- 在命令行中运行 python pixivspider 即可开始下载。下载成功和下载失败的插画会分别记录到数据库中的 illust 和 download_failed 数据表中。
- 去 pixivspider-data/downloads 目录收取已经下载的插画。
导入
主要是用来转移原有的数据,也可用于初始化画师 ID 列表。
- 在 pixivspider 文件夹所在目录下提供一个存有画师 ID 的文本文件 PixivIdList.txt,格式为每行一个 ID,运行
python pixivspider --import
命令进行导入。因为 ID 不能与已有的重复,所以在导入前要确认数据库中是否存在与 PixivIdList.txt 文件中相同的 ID,以免导入失败。
其他
- 下一次运行时会自行下载所有失败的插画,当成功下载后会自动从失败记录中移除。
- 程序使用数据库中的记录判断插画是否已经下载,因此可以随意处理 downloads 目录中已下载的插画。下次下载时仍会跳过这些文件。
- 向不知道是否存在的读者们求 star (๑•́ ₃ •̀๑)
※2019-07-07:今天脚本拿来一跑发现登录不了,原来 P 站上了股沟 reCAPTCHA…成天搞事情。试了试发现(用浏览器插件)把 cookie 提取出来,把 P 站中 PHPSESSID 字段的 value 和 expire 提取出来覆盖到 PixivCookie.txt 中就可以以已登录的身份继续下载乛◡乛。顺便提供一份 PixivCookie.txt 的模板
# Netscape HTTP Cookie File # http://curl.haxx.se/rfc/cookie_spec.html # This is a generated file! Do not edit. .pixiv.net TRUE / TRUE (expire值覆盖) PHPSESSID (value值覆盖) .pixiv.net TRUE / TRUE 1719677052 p_ab_d_id 1000246005 .pixiv.net TRUE / TRUE 1719677052 p_ab_id 7 .pixiv.net TRUE / TRUE 1719677052 p_ab_id_2 1

不错的工具,感谢分享~话说博主招不招友链啊~
吼啊
ok.已添加。
友链页面:https://moeblog.top/Blog/friend-links.html
名称:MoeBlog
地址https://moeblog.top
一句话签名:不要忘记,当初为何出发。
已经添加😀